RAVE models encode data from the audio domain into highly compressed latent representations. Based on statistical information retrieved from these encodings, a speculative compositional practice can be established inside the latent space of the models. It is derived from the improvisation tactics empirically proven in Latent Jamming.
For a proof of concept (POC), I have written UnRAVEl, a set of Python scripts, that cover a three step process:
- audio data encoding: 1-n audio files are encoded into arrays in the shape of a model’s latent space.
- generation of synthetic data: 1-n encodings are evaluated for their data distribution. Based on the results, arrays of synthetic data are generated which are used to populate preset patterns and apply alterations to these patterns.
- decoding of synthetic data into audio data: 1-n generated/ synthetic data arrays are being decoded and up sampled back to the audio domain using the same model as in the encoding process.
Considerations and hypotheses
Prior distribution vs. encoding audio
While models contain statistics learned during training, encoding real world audio data through a model for evaluation can be more robust when it comes to deviations from the original data set. However, domain data similar to what the model has seen during training should yield most truthful statistics for informing synthetic data generation.
Distribution
VAEs like RAVE assume a Gaussian latent prior. Generating synthetic data using mean and standard deviation retrieved from the encodings should create truthful results.
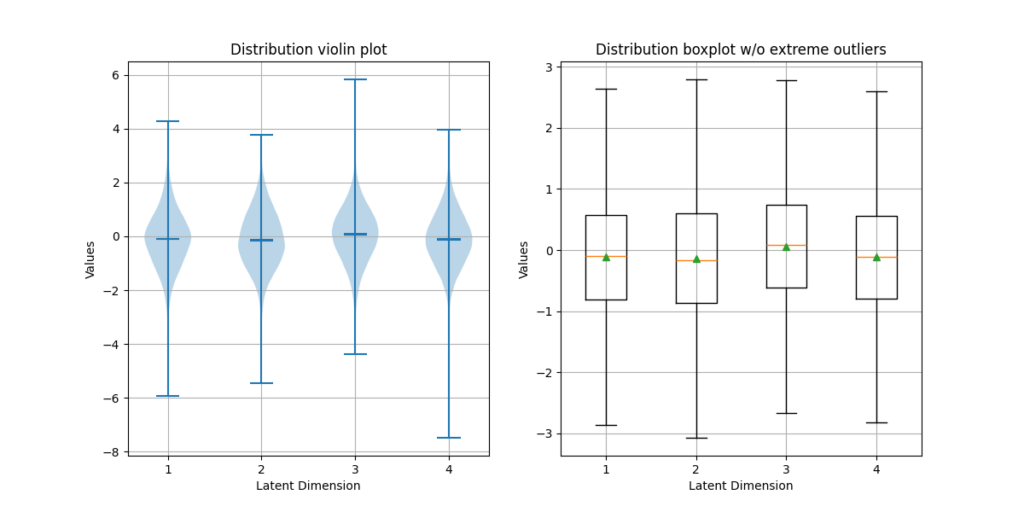
In UnRAVEl, this is covered by normal distribution; other distribution types, e.g. uniform or correlation-based, are experimental but, depending on the model, can create more interesting output since they sample from a different value range and logic.
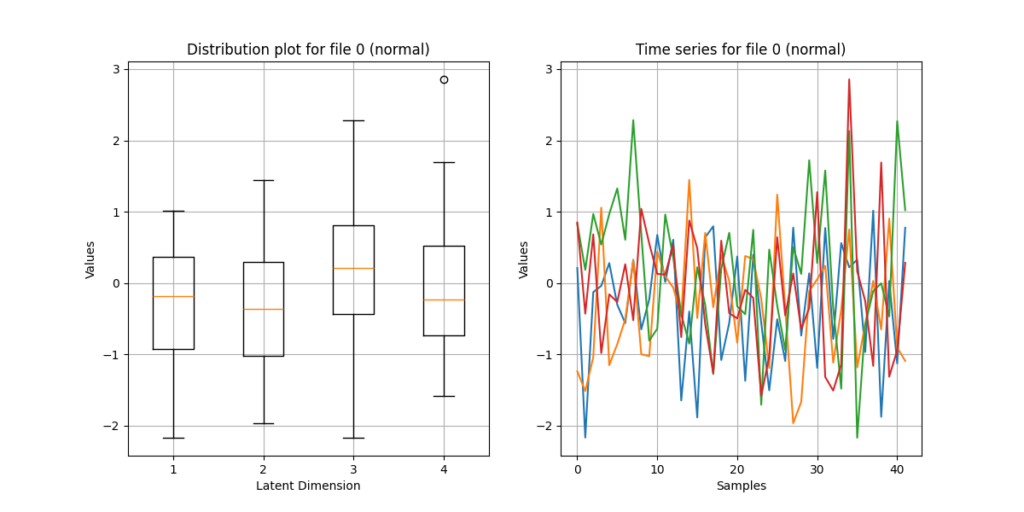
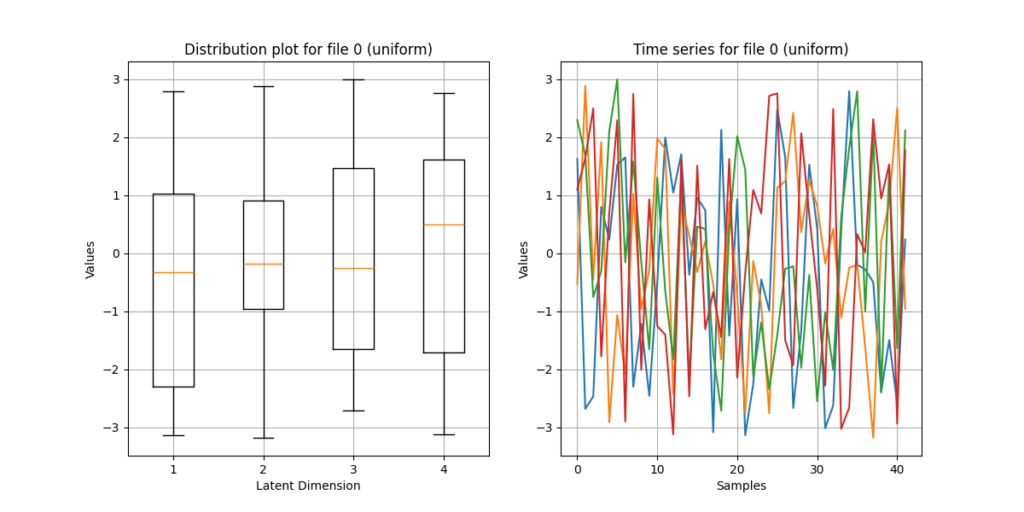
Tempo quantizing
Latent embeddings created with RAVE are highly compressed representations of audio domain data. A sample rate of 44.1KHz corresponds to 21 data points times the number of latent dimensions in the model’s configuration. The audio domain resolution is high enough to be more or less irrelevant for tempo considerations, however, with the low resolution in latent space, limitations to achievable tempi are expressed by:
60 * (model sample rate / model compression) / latent data points
For example:
60 * (44100 / 2048) / 11 = 117.45 BPM
This leads to the following quantized tempi (in 4ths, 8ths for double time) achievable by looping k amount of latent data points.
| k | Tempo BPM | Double time | Audio |
|---|---|---|---|
| … | … | … | … |
| 7 | 184.57 | – | Example |
| 8 | 161.49 | 322.98 | Example |
| 9 | 143.55 | – | Example |
| 10 | 129.19 | 258.38 | Example |
| 11 | 117.45 | – | Example |
| 12 | 107.66 | 215.32 | Example |
| … | … | … | … |
Patterns
The compositional approach in latent space exemplified in UnRAVEl is based on high level structural considerations, e.g. repeating (parts of) data arrays, replacing data points and/or slightly altering them while boundaries like value distribution or tempo quantizing need to be considered.
Compositional ideas can be established defining patterns; in UnRAVEl four patterns have been implemented as a starting point.
fibo
A given array of shape (data points, latent dimensions) is repeated along the fibonacci series of integers. 1 corresponds to the first row in the array, 2 corresponds to the first two rows in the array, …, 8 corresponds to rows 0-7 and so on.
orale
An approximation to a standard sequence in electronic music building an array using a 3:1 scheme where the original array is repeated three times and a fourth time with subtle changes applied to its values. This sequence is then repeated and altered again in the same scheme of 3:1.
blender
Two arrays are blended into one another by replacing single data points sequentially after n repetitions, starting with the first value in the first dimension, followed by the first value in the second dimension and so on until the last value in the last dimension has been reached.
swapper
Values of randomly picked data points in two arrays of the same size are swapped. The altered array is repeated n times.
Use in Pure Data
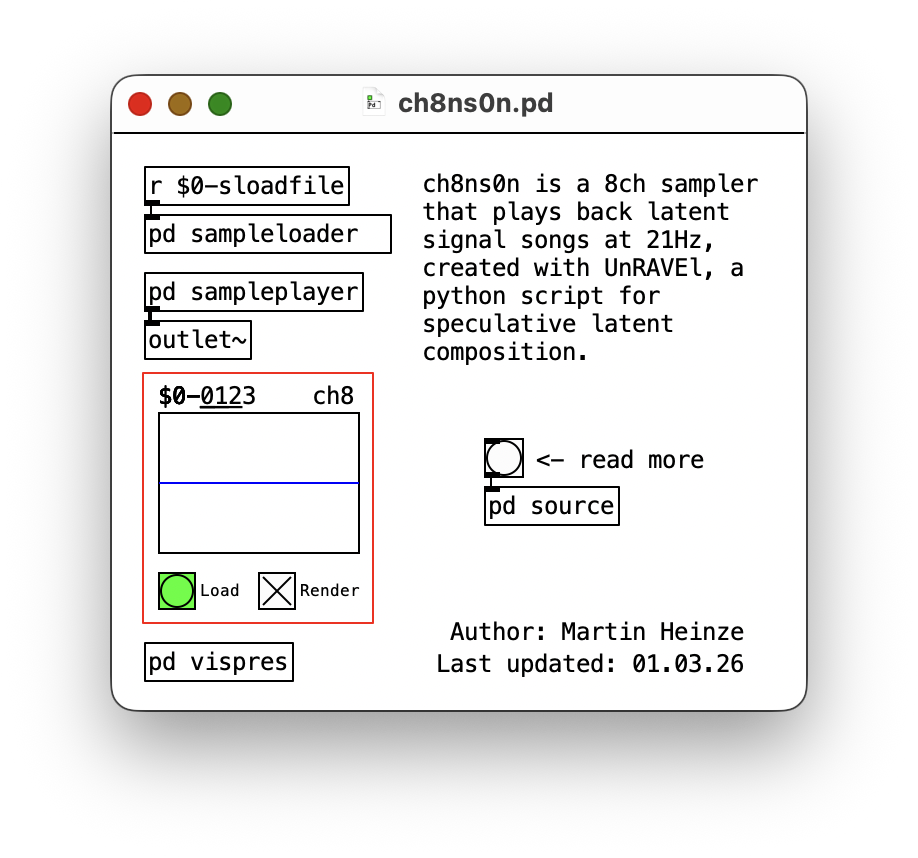
UnRAVEl generates .npy arrays that can be decoded to the audio domain using the dedicated script. Alternatively, latent audio files are being written; these are basically multi channel (= latent dimensions), double precision (= for values outside -1/+1 boundary) .wav file at e.g. 21Hz resolution (if data source was 44.1KHz). This format works with an abstraction I’ve written in Pure Data: ch4ns0n/ch8ns0n (note that only models with 4 and 8 latent dimensions are supported, but the component is fairly easy to extent).
Acknowledgements
- Thanks to Jordi Pons for the thought exchange.